[JS] 非同步處理
Change Log
- 2023:Initial version
- 2026/01/14:Update the whole article structure and content.
關於非同步的概論,可以參考我在 2025 iThome 寫的文章。
對於初次了解同步與非同步的人,該篇前半段會比較親民一點,因為我盡量以譬喻的方式講解同步與非同步。
該篇後半段的部分則是著重於說明:
- async/await
- macrotask 與 microtask
本篇於 2026/01/14 更新後著重在 Event Loop、Callback Function、Promise、async/await 的介紹與範例。
Event Loop
為何 event loop 重要?因為 event loop 是 JS 非同步運作相當重要的一個環節。
理解 event loop 必須得先順過整個非同步的運作流程,所以會 event loop,基本 JS 的非同步就不成問題了。
這裡先簡單講一下,很多人以為 JS 一開始就是非同步的語言,其實不然。
從古至今 (對,今天依舊),JavaScript 一直都是個單執行緒 (single-threaded) 的語言,也就是一次只能做一件事情的語言。
初學 JS 的應該會很常聽到程式碼的運作是按著撰寫的順序執行,這就是單執行緒,也是我們所謂的「同步 (synchronous)」。
但同步的缺點很明顯,遇到一行需要花比較多時間去執行的函式 (例如:網路請求、讀取檔案...) 時,整個程式碼的後續就會被卡住,必須等前面的函式執行完畢才能繼續往下執行。
很久以前的網頁就有這個問題,所以會 loading 很久都沒畫面,而現今因為非同步的出現,在一些內容需求負載比較大的 code 或任務運行時,我們仍得以看到其它部分的網頁內容。
但這種因為同步而產生的等待,我們稱為「阻塞 (blocking)」。
整個非同步的流程有三個必須記得的專有名詞:
- Call stack
- Web API
- Callback queue
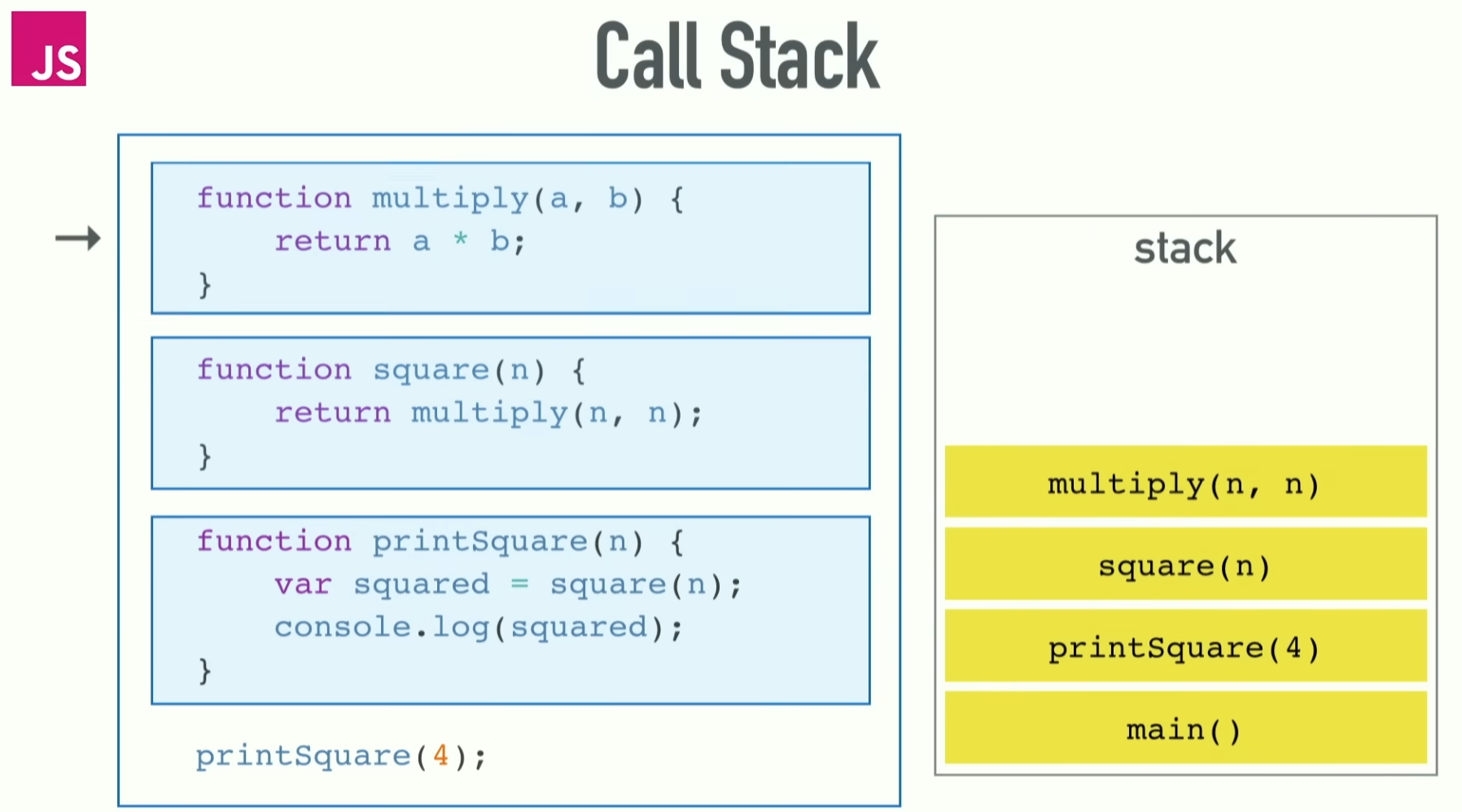
Call stack 其實是 JS engine 的一部分,所以在非同步誕生之前它就已經活在同步裡了。
學過資料結構的都知道,stack 是一種 LIFO (Last In First Out) 的結構,意思是說最後進去的東西會最先被取出來。
具體來說是,被調用的函式在執行時,JS engine 會建立一個對應的 execution context (執行上下文),並將該 execution context push 進 call stack。
當函式內部再調用其他函式時,新的 execution context 會依序被 push 進 stack。
最後被 pop 出來的 execution context,會是最先被 push 進 stack 的那一個。
在同步執行模型下,由於 JavaScript 是單執行緒語言,call stack 的執行順序在多數情況下,會與程式碼撰寫的順序高度一致。
因此我們常聽到 JS 的運作是「由上而下」隨著程式碼的撰寫順序執行的 (但其實大多數語言也都是這樣)。
Web API 跟 Callback queue 才是非同步誕生的關鍵,但他們本身並不是 JS engine 的一部分,而是瀏覽器或 NodeJS 這種 JavaScript 執行環境提供的功能。
這裡解惑一下,沒人規定 JavaScript 只能用 NodeJS 來執行喔,NodeJS 只是提供一個環境而且絕大多數 web developer 愛用它開發,不然還有一些小眾的執行環境 (像是 Deno) 可以用。
所以嚴格來說,JavaScript 語言本身並不負責實際的非同步等待與 I/O 操作 (JS 還是有提供像 Promise 這樣的非同步語言抽象的~),而是必須搭配適當的執行環境 (像是瀏覽器、NodeJS) 才能完成非同步行為。
Web API 是指什麼?
本質上來說,它是一組由 JavaScript 執行環境提供的「非同步功能介面」,負責銜接 JS engine 與各種非同步能力,例如 setTimeout、DOM 事件監聽器 (event listener)、AJAX 請求等。
以 setTimeout 為例,當我們在 JavaScript 中呼叫它時,這個 API 呼叫本身會同步地在 Call stack 中執行,而 JS 執行環境則會在此時將計時器與對應的 callback (即我們寫在 setTimeout 裡等待時間到要執行的內容) 註冊給 Web API,由 Web API 在背景處理計時任務。
這樣一來,Call stack 就不需要等待計時器結束,後續的同步程式碼仍然可以繼續往下執行,避免阻塞整個程式流程。
當這段非同步任務由執行環境處理完成後,對應的 callback (重申一次,就是等待非同步功能執行完畢後要做的事) 會被放入佇列中等待執行,這個佇列通常被稱為 callback queue。
而 event loop 這時就閃亮登場,它會負責協調「等待 Call stack 空閒,並安排 callback 回到 Call stack 去執行」。
簡單來說,event loop 會像個守衛一樣持續監控 Call stack 的狀態,當 Call stack 為空時,便從佇列中取出下一個可執行的 callback,並將其推入 Call stack 中交由 JS engine 執行。
至此,我們完成一次偉大的非同步流程。
我相當相當強烈推薦大家看一下這段 Philip Roberts 在 JSConf EU 2014 的演講影片。
實際例子看非同步
Philip Roberts 在 JSConf EU 介紹 event loop 的例子:
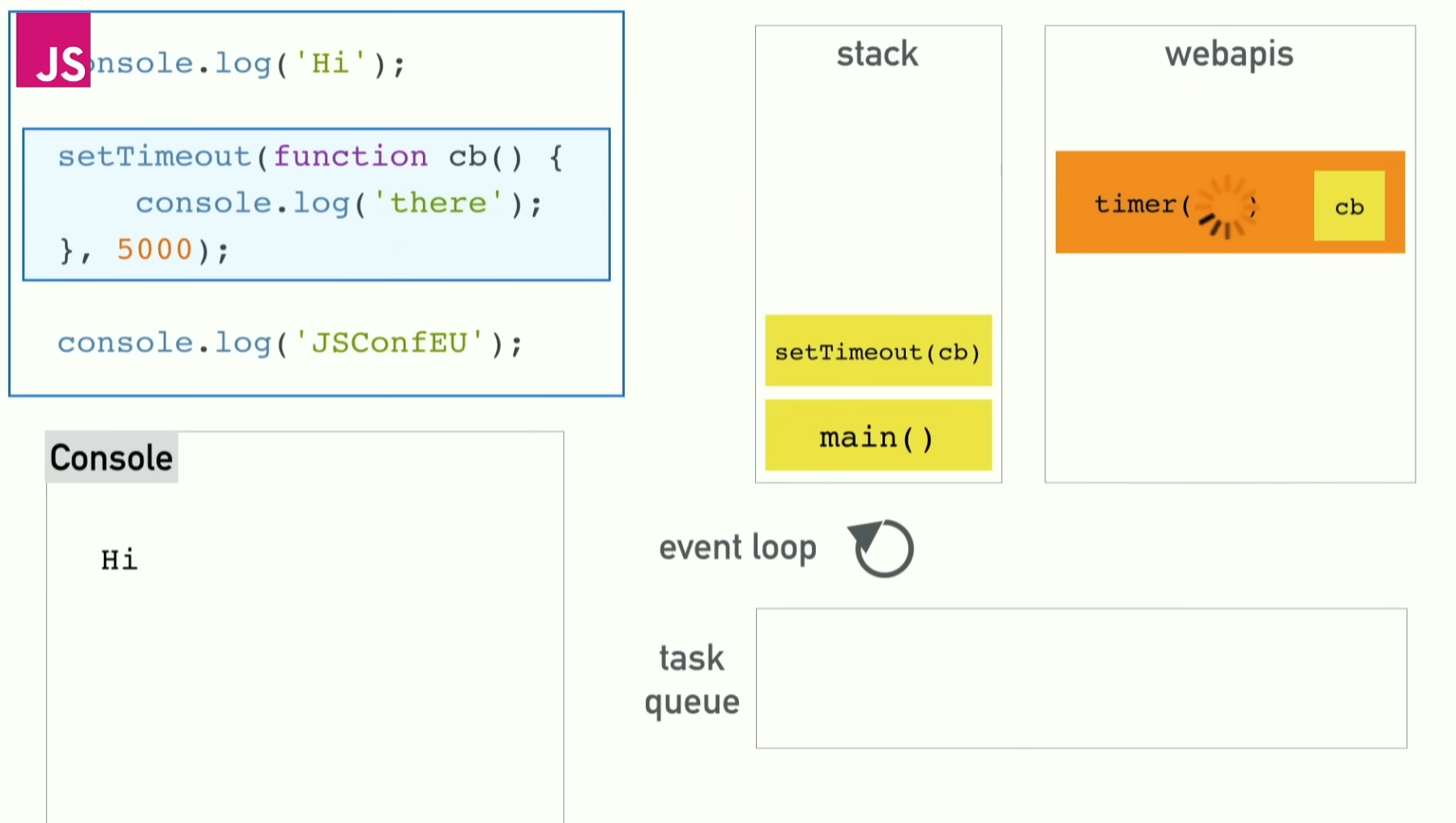
console.log('hi');
setTimeout(function cb(){
console.log('there');
}, 5000);
console.log('JSConfEU')
這段 code 的產出結果順序將會是:
'hi''JSConfEU''there'
按照前面講的非同步來解釋事情是怎麼發生的:
console.log('hi')被推入 Call stack 並同步執行,執行完畢後從 Call stack 中移除。setTimeout被推入 Call stack,同步執行完畢後,JS 執行環境將計時器與對應的 callback 註冊給 Web API,接著setTimeout呼叫本身從 Call stack 中結束。console.log('JSConfEU')被推入 Call stack 並同步執行。- 五秒後,計時器完成,對應的 callback (
console.log('there')) 被放入 callback queue 中等待執行。 - 當 Call stack 為空時,event loop 會將佇列中的 callback 安排進 Call stack,交由 JS engine 執行,輸出
'there'。
那 setTimeout(func, 0) 呢?
輸出結果順序依然相同,因為即使延遲時間為 0,setTimeout 的 callback 仍然會被排入佇列中,必須等到目前的同步程式碼執行完畢,並且 Call stack 為空時,才有機會被 event loop 安排執行。
Callback Function
既然非同步會提到 callback function,那就有必要釐清 callback function 本身是什麼。
許多文章在解釋 callback 時,通常會這樣描述:
將一個函式 B 作為參數傳入另一個函式 A,並由 A 在適當的時機呼叫 B。
這樣設計通常有兩個目的:
- 讓函式 B 只在滿足特定條件時,才被「被動地」執行。
- 明確控制函式之間的執行順序。
白話一點來說,就是「先做完 A,才有機會執行 B」。
回想前面 setTimeout 的例子,這正是一種典型的 callback 應用:我們先呼叫 setTimeout 註冊計時器,等計時器完成後,才由執行環境安排執行對應的 callback (console.log('there'))。
這裡要特別釐清一個很重要的觀念:
不是所有 callback function 都代表非同步操作。非同步操作完成後要執行的邏輯,剛好符合 callback function 的定義而已。用集合的概念來看,可以表示為:
非同步 callback ⊆ callback function。也就是說,非同步 callback 只是 callback function 這個廣泛概念底下的一個子集。
這裡我們先寫個簡單的「非同步」callback 範例,下面章節會用:
fetchData(function (result) {
setTimeout(() => {
console.log('step 1:', result)
setTimeout(() => {
console.log('step 2: process done')
setTimeout(() => {
console.log('step 3: finished')
}, 1000)
}, 1000)
}, 1000)
})
Promise
試想一下,剛剛的例子僅是 A 執行完去執行 B,但如果今天 B 執行完還要執行 C、D、E...呢?
恐怕一不小心就迷失在茫茫的 callback 大海中了。
看看我們上方最後寫的那個三層 setTimeout 的非同步 callback 範例,是不是讓人看得頭昏眼花?
這就是眾所皆知的 「callback hell」。
Promise 是 JavaScript 在語言層級提供的一種非同步流程抽象,用來改善非同步 callback 在巢狀結構下的可讀性與可維護性。
需要注意的是,Promise 解決的是「非同步流程的表達方式」,而不是實際的非同步等待或 I/O 行為。
一個 Promise 物件通常會有三種狀態:
- pending:尚未完成,仍在處理中
- fulfilled:處理成功
- rejected:處理失敗
Promise 會透過 then 來接收成功的結果,並串接下一步的處理流程;若發生錯誤,則可透過 catch 來統一處理失敗的情況。
因此,Promise 的使用方式通常會長得像這樣:A().then(B).catch(handleError)。
把前一段的程式碼改成 promise 會像這樣:
function fetchDataPromise() {
return new Promise((resolve) => {
setTimeout(() => {
resolve('DATA_FROM_SERVER')
}, 1000)
})
}
fetchDataPromise()
.then((result) => {
console.log('step 1:', result)
return new Promise((resolve) => {
setTimeout(() => {
resolve()
}, 1000)
})
})
.then(() => {
console.log('step 2: process done')
return new Promise((resolve) => {
setTimeout(() => {
resolve()
}, 1000)
})
})
.then(() => {
console.log('step 3: finished')
})
async/await
基於我在 iThome 2025 文章裡對 async/await 做了很詳細的說明,這裡只節錄重點。
Promise 雖然相當程度地幫助了工程師脫離非同步流程下的 callback hell,但在實際使用上,仍然會因為過多的 then 與 catch 而讓程式碼看起來不夠直覺。
因此 async/await 這個基於 Promise 的語法糖就這樣誕生了。
這裡要特別注意,它是語法糖語法糖語法糖,很重要,說三次,底層邏輯還是 Promise。
async/await 最大的特點,很多人都會說是「讓我們可以用看似同步的語法來撰寫非同步的內容」。
呃,不能說錯,但不夠準確。
更準確地說,是讓 async function 內部的非同步流程,看起來像同步程式碼一樣由上而下執行。
這點在閱讀與撰寫程式碼時,能大幅降低心智負擔。
await 的作用,並不是讓整個程式停下來等待,而是讓 async function 內部後續的程式碼暫停執行。
當 await 等待的 Promise 進入 fulfilled 或 rejected 狀態時,對應的後續程式碼 (也就是 await 那行後面的內容) 會被安排進 microtask queue,等待 event loop 在適當時機將其推回 Call stack 繼續執行。
也正因如此,對 async function 內部來說,程式碼的執行流程看起來像是同步的;但對於 async function 外部的程式碼而言,它依然是一個非同步行為,並不會阻塞整個程式的執行。
另外值得提一下的是,Promise 有 catch 來捕獲錯誤,那 async/await 呢?
答案是用其他語言也常見到的 try...catch。
嚴謹一點還會有個 finally,用來處理不論成功或失敗都會執行的邏輯。
所以一個 async function 大概長這樣:
async function myAsyncFunction() {
try {
const result = await somePromiseFunction()
// do something with result
} catch (error) {
// handle error
} finally {
// always execute this block
}
}
function wait(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms)
})
}
async function run() {
const result = await fetchDataPromise()
console.log('step 1:', result)
await wait(1000)
console.log('step 2: process done')
await wait(1000)
console.log('step 3: finished')
}
run()
我看過有人因為誤解 async/await 的意義,以為只要加上 await,就一定會「等那行程式碼跑完」才繼續往下執行,因此把本來就是同步的 function 也加上 await。
先說,這樣寫當然可以執行,JavaScript 也不會報錯,但那是因為 await 對任何值都有效。什麼意思?
簡單來說,若 await 的對象不是 Promise,JavaScript 會立刻將該值包成一個已 fulfilled 的 Promise (等同於 Promise.resolve(value)),因此行為上看起來就和沒有加 await 幾乎一樣。
換句話說,在同步情況下,加不加 await 對執行結果沒有任何實質影響。
而在實務上,把本來就是同步的 method 寫成 async/await,除了徒增閱讀與理解成本外,並不會帶來任何實際好處。