
演算法與前端
LeetCode 上有一題 217. Contains Duplicate,用意是檢查陣列裡的數字是否有重複出現,若有就 return true,反之就 return false。
這基本在前端應用上最容易聯想的就是陣列的元素去重。
概念上這種跟陣列相關的問題第一個會直覺想到用陣列自己本身的 methods 去解決,比如 leetcode 217 這題可能會直覺想到 includes:
function containsDuplicate(nums: number[]): boolean {
const checked: number[] = []
for (const num of nums) {
if (checked.includes(num))
return true
checked.push(num)
}
return false
}然後就發現 includes 通過了絕大部分的測試,但在遇到超~~~ 多內容的陣列就會遇到 TLE (Time Limit Exceeded)。
所以改用一個不是陣列本身的方式來解題,透過 new Set 來解題:
function containsDuplicate(nums: number[]): boolean {
return new Set(nums).size !== nums.length
}可以看到它順利通過 leetcode 的整整 77 個大測試,甚至執行速率還不錯。
造成這種差異的就在於使用 includes 的方式的複雜度是 ,而 new Set 的複雜度是 。
如果忘記複雜度是什麼或簡單怎麼計算,沒關係,這等等會講。
但這裡只要記住一件事, 所耗費的時間在 足夠大時是會遠大於 的。
其實簡單舉個 , 會耗費 100 時間單位, 只會耗 10 個時間單位,基本就能稍微感受到其差異了。
複雜度分析
簡單複習一下複雜度,其實大家簡單回憶一下複雜度會回想起複雜度其實分為時間複雜度跟空間複雜度,但基本討論的都還是時間複雜度最多,因為時間複雜度通常是影響程式效能的主要因素。空間複雜度雖然也重要,但一般要資料量非常大,或是記憶體非常有限的情況下,才會特別注意空間複雜度。
所以我們這裡就只講時間複雜度。
關於複雜度的討論,基本就是大家耳熟能詳的 Big O notation,用一個簡單的代表來衡量演算法在 趨近於無限大時在最壞的情況下的表現。
對於 Big O,他還有個 Big Ω 跟 Big Θ 的姐妹,用白話一點的說法來記憶,前者可以當作是演算法在最佳的情況下的表現,後者則可以視為平均表現,但這是不嚴謹的說法,不過他們也不在這次的討論中,因為通常大家最關心的是演算法在最壞情況下的表現,所以這裡也不贅述其餘二者。
對於複雜度分析,我們回到前面 leetcode 217 的例子。
剛剛提到 includes 的方式其複雜度為 是怎麼算的?
其實就是估算 筆資料在最壞情況下,核心操作總共會被執行幾次。
function containsDuplicate(nums: number[]): boolean {
const checked: number[] = []
for (const num of nums) { // O(n):走訪每個元素
if (checked.includes(num)) // O(n):includes 會線性掃描整個陣列
return true
checked.push(num)
}
return false // 總計 O(n) × O(n) = O(n²)
}至於 new Set 的方法為何是 ?
在於 new Set(nums) 建構時需要走訪全部 個元素,而每次插入 Set 的操作為 ,因此整體為 。
function containsDuplicate(nums: number[]): boolean {
// new Set(nums):走訪 n 個元素,每次插入為 O(1),整體 O(n)
return new Set(nums).size !== nums.length
}所以這就是一個最基本的複雜度分析。
而常見的複雜度種類可以稍微概括如下:
- :常數時間複雜度,無論輸入的規模多大,執行時間都是固定的。
- :對數時間複雜度,當輸入規模增長,執行時間呈對數成長。
- :線性時間複雜度,執行時間與輸入的規模成正比。
- :線性對數時間複雜度,當輸入規模增長,執行時間以 乘以 的速率增長。
- :多項式複雜度,當輸入規模增長,執行時間呈多項式成長。
- :指數時間複雜度,當輸入規模增長,執行時間呈指數成長。
對於前端實務開發來說,最常不小心踩到的就是多項式複雜度,舉例來說我們可能都看過 .map() 裡面呼叫 .find() 之類的寫法,簡單、方便,好用一直用。
但這其實就是一個迴圈套另一個迴圈。
一般會沒感受到它帶來的效能差異是因為經手的資料量挺小的,但只要資料從 50 筆變成 5000 筆,畫面大概就開始卡了。
對於前端來說,我們一些很常用的方法也都可以以複雜度衡量:
| 程式碼 | 速度 | 為什麼 |
|---|---|---|
arr[5] | 用位置直接拿 | |
arr.find(item => ...) | 從頭掃到尾 | |
arr.filter(...) | 每個看一遍 | |
arr.sort() | 排序就是這個等級 | |
.map() 裡面套 .find() | 迴圈套迴圈 |
還有一個常見的寫法類似這樣:arr.filter().map().reduce(),可能會覺得其複雜度為 ?
但其實它只是把陣列跑了三遍,一遍過濾、一遍轉換、一遍計算,每遍都是從頭到尾走一次,加起來是 ,在 Big O 裡常數會被忽略,所以整體仍然是 ,不是 。
真正會用多項式計算的是巢狀結構,比如前述的 .map() 裡面套 .find()。
前端開發裡的資料結構
其實用 JS 講 data structure 略有些難受,因為 JS 真的是個挺神奇的語言。
大家都知道在 JS 裡 array 是 object 的一種,但對應學術裡的 data structure,object 其實是 hash table,而 array 則依舊是 array,其原因來自於現在的 JS engine 會針對 array 做一些優化。
就我自己的理解是它會偷偷觀察我們寫 JS array 的方式去更換底層結構:
- index 是連續整數、元素型別一致 → 換成連續記憶體,就是學術上的 array
- 中間有空洞、或混了不同型別 → 退回 hash table
所以總之用 JS 說資料結構真的有一丟丟反直覺。
但在一些前端常討論的內容還是可以稍微感受到資料結構的強大。
Object
如同前述所說,JS object 其實底層是 hash table。
Hash table 這個資料結構的特點是存資料時,key 會先經過一個 hash function 轉換成一個數字,這個數字就是該資料在記憶體中的位置(index)。
之後要查找時,同樣把 key 丟進 hash function,直接算出位置跳過去,就不需要從頭掃,因此查找的複雜度在一般情況下是 。
這個 hash 概念其實跟登入系統輸入密碼時的 hash 是一樣的,不過登入系統這邊是為了安全性更多一點。
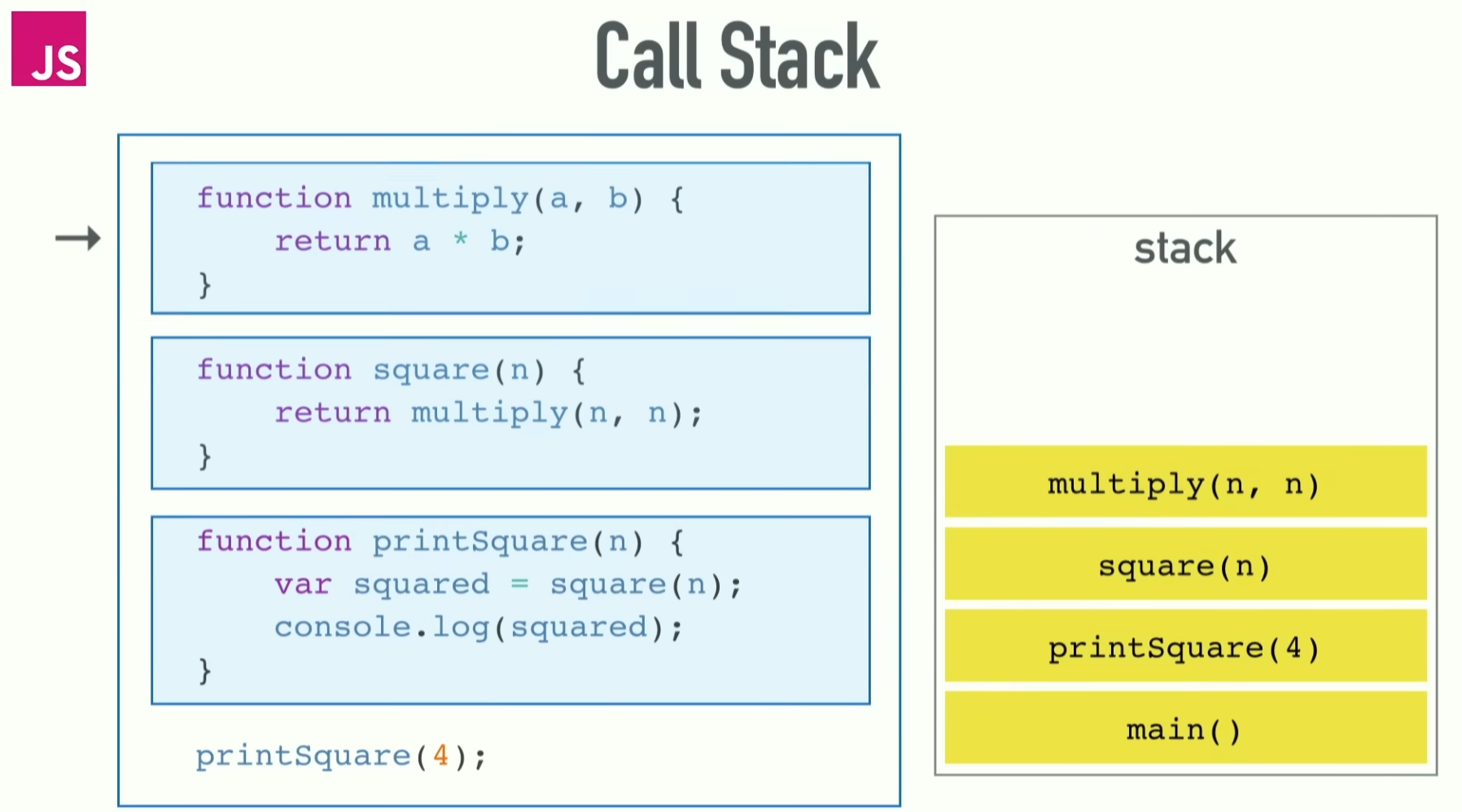
Call stack
前端在探討非同步時多少都會提到一點 call stack。
既然它掛著 stack 的名字,學過資料結構的都知道,stack 是一種 LIFO (Last In First Out) 的結構,意思是說最後進去的東西會最先被取出來。
用一個我一直覺得是非同步經典影片裡的截圖來看 call stack:
Callback queue
Callback queue 是非同步探討一定會講到的內容,基本上講的是當非同步任務由執行環境處理完成後,對應的 callback 會被放入佇列中等待執行,這個佇列通常被稱為 callback queue。
Queue 基本常拿出來跟 stack 做對比,前面提到 stack 是 LIFO (Last In First Out),queue 剛好反過來是 FIFO (First In First Out),也就是先進先出。
因此 callback queue 概念上就是越先進去的 callback 會越早被 event loop 給抓出來排進 call stack。
至於 callback queue 嚴格意義上又會被分 macrotask queue 與 microtask queue,這是非同步要探討的問題,這裡也不贅述。
DOM tree
前端最基本的骨架 DOM tree 也是一個經典資料結構的應用 - tree。
舉例來說,<html> 是根節點,往下分出 <head> 和 <body>,<body> 再往下分出各個子元素,層層展開:
html
├── head
│ └── title
└── body
├── h1
└── div
└── pquerySelector 本質上就是在這棵樹上透過 DFS (Depth-First Search) 去找節點,一路往最深的子節點鑽,找不到再回頭換下一條路,直到找到第一個符合的元素為止。
所以在最壞的情況下,querySelector 就是把整個 DOM tree 都給爬完,複雜度是 。
因此有時候會建議把搜尋的範圍縮小,比如:
const container = document.getElementById('app') // 已經有參考了
container.querySelector('.target') // 只走 container 底下的樹但更根本的作法是透過 getElementById 來選取 DOM node。因為 id 在整份文件裡是唯一的,瀏覽器在解析 HTML 時通常會順便維護一張 id → 節點的 hash table,記住每個 id 對應的節點位置。查找時直接從 hash table 拿到該節點的參考,不需要從根節點一路遍歷下去——不過這屬於瀏覽器實作層面的優化,規格本身並沒有強制要求。
實務上探討一下演算法與資料結構 (Vue 為例)
例子一:computed 的運算
假設在做一個文章列表,每篇文章有一個作者 ID,現在想把作者名稱補上去,最直覺的做法大概是這樣:
<script setup>
import { computed } from 'vue'
const props = defineProps({
posts: Array, // [{ id: 1, authorId: 'a1', title: '第一篇文章' }, ...]
authors: Array, // [{ id: 'a1', name: '小明' }, ...]
})
const enrichedPosts = computed(() =>
props.posts.map(post => {
const matched = props.authors.find(author => author.id === post.authorId)
return { ...post, authorName: matched?.name }
})
)
</script>.map() 裡面用 .find() 查作者名稱,邏輯清楚、撰寫直覺。
但對每一個 post 而言,.find() 都要把 authors 從頭掃到尾。
如果有 500 篇 post、100 個 author,每次 computed 重算就是 500 × 100 = 50000 次比較,嚴格來說其複雜度為 ,但由於複雜度討論的是最壞情況,當 與 規模相近時即退化為 ,因此慣例上會直接以 稱之。
而且只要 posts 一變動(比如搜尋結果改變),整個 computed 就會重跑一次。
這在資料量大時就是個災難。
解決這種在資料量大時極耗效能的方式是改成先建一個「索引簿」(也就是 Hash Table),下面的查找複雜度為 :
<script setup>
import { computed } from 'vue'
const props = defineProps({
posts: Array, // [{ id: 1, authorId: 'a1', title: '第一篇文章' }, ...]
authors: Array, // [{ id: 'a1', name: '小明' }, ...]
})
// 先把 authors 建成一個索引簿(plain object)
// key 是作者 ID,value 是作者物件
// 這一步跑一遍 authors 就做完了
// 結果長這樣:
// {
// a1: { id: 'a1', name: '小明' },
// a2: { id: 'a2', name: '小華' },
// ...
// }
const authorIndex = computed(() =>
Object.fromEntries(props.authors.map(author => [author.id, author]))
)
// 現在查作者名稱不用掃了,直接用 ID 去索引簿裡撈
const enrichedPosts = computed(() =>
props.posts.map(post => ({
...post,
authorName: authorIndex.value[post.authorId]?.name
}))
)
</script>例子二:v-for 裡寫 v-if
另一個可能也是大家 vue 開發比較容易遇到的:
<template>
<div v-for="item in items" :key="item.id">
<span v-if="item.active">{{ item.name }}</span>
</div>
</template>在這個寫法下,Vue 還是得跑完 items 的每一圈去判斷 v-if 的條件,就算 1000 筆裡面只有 10 筆是 active 的也一樣。
比較好的做法:先過濾好再丟給 v-for。
<script setup>
import { computed } from 'vue'
// 先把 active 的篩出來,交給 computed 快取
const activeItems = computed(() =>
props.items.filter(item => item.active)
)
</script>
<template>
<!-- 只跑 active 的那些,DOM 節點也少很多 -->
<div v-for="item in activeItems" :key="item.id">
<span>{{ item.name }}</span>
</div>
</template>如果對上面這個比較無感的話,那有一個變體應該比較常見。
<script setup>
// 後端只給 createdAt(timestamp),沒有給 isNew
// 只好前端自己算:7 天內發布的算新文章
function isNew(post) {
const sevenDaysAgo = Date.now() - 7 * 24 * 60 * 60 * 1000
return post.createdAt > sevenDaysAgo
}
</script>
<template>
<div v-for="post in posts" :key="post.id">
<!-- ❌ anti-pattern:每次渲染都重新呼叫 isNew 並重新計算時間 -->
<span v-if="isNew(post)">{{ post.title }}</span>
</div>
</template>這種一樣可以先計算完再丟給 v-for:
<script setup>
import { computed } from 'vue'
// ✅ 只算一次,結果由 computed 快取起來
const newPosts = computed(() => {
const sevenDaysAgo = Date.now() - 7 * 24 * 60 * 60 * 1000
return props.posts.filter(post => post.createdAt > sevenDaysAgo)
})
</script>
<template>
<div v-for="post in newPosts" :key="post.id">
<span>{{ post.title }}</span>
</div>
</template>效能 vs 維護/易讀性
這其實滿主觀意識的。
但前面在講演算法跟資料結構在探討複雜度時說的都是「當 趨近於無窮大時」。
因為在少量資料時,複雜度的衡量意義其實不高。
舉例來說 跟 ,一個是 、一個是 ,以複雜度來說會預期前者更好,但在 之前,後者都是優於前者的。
所以這說明當資料量少時,去探討複雜度的意義可能不大,因為可能兩者差不多或更有甚者是複雜度差者在小資料量時表現更好。
但這個資料量多小,就滿看實際應用場景的。
但總之在資料量小時,我認為是可以捨棄複雜度的,因為其實效能相差不大,而轉向使用更通俗好懂的撰寫方式。
// 這個超好讀,一眼就知道在幹嘛
const userName = users.find(user => user.id === currentId)?.name
// 這個比較快,但得多想一秒才能理解
const userIndex = Object.fromEntries(users.map(user => [user.id, user]))
const userName = userIndex[currentId]?.name過早優化是萬惡之源 - Donald Knuth
上面是找資料找到的 XD
但總之這概念提倡的是在正確的時間做正確的優化。
但這正確的時間是什麼時間其實也是帶點主觀的。
資料庫
每次打 API 拿到的 JSON,其實一般都可以反映資料庫的設計決策。
我們可能常見到這兩種 API response 長相:
// 巢狀:關聯資料直接內嵌
{
"id": 1,
"title": "第一篇文章",
"author": { "id": "a1", "name": "小明" },
"tags": ["Vue", "JS"]
}// 扁平:只給 id,關聯資料要自己再去拿
{
"id": 1,
"title": "第一篇文章",
"authorId": "a1",
"tagIds": ["tag_vue", "tag_js"]
}兩者的差異在於資料庫的正規化程度,也對應到兩種不太一樣的資料庫儲存設計。
正規化
假設後端用一張表存所有資料,巢狀 response 對應的原始表可能長這樣:
| post_id | title | author_id | author_name | tags |
|---|---|---|---|---|
| 1 | 第一篇文章 | a1 | 小明 | Vue, JS |
| 2 | 第二篇文章 | a1 | 小明 | JS |
正規化就是把這張表一步步整理乾淨的過程,目的是提升儲存效率、減少資料異常。
1NF
第一正規化是為了讓每一張表都有一個 primary key,且每個欄位只存一個值。
比如這裡 tags 欄位塞了多個值,資料庫無法直接查詢或索引裡面的單一標籤。
改成每個值獨立一筆:
| post_id | title | author_id | author_name | tag |
|---|---|---|---|---|
| 1 | 第一篇文章 | a1 | 小明 | Vue |
| 1 | 第一篇文章 | a1 | 小明 | JS |
| 2 | 第二篇文章 | a1 | 小明 | JS |
2NF
第二正規化是為了消除 1NF 後產生的重複資料。
tag 拆開後,title、author_name 跟 tag 根本沒關係,卻被迫跟著重複出現。依據 2NF 可以拆成兩張表:
posts
| post_id | title | author_id | author_name |
|---|---|---|---|
| 1 | 第一篇文章 | a1 | 小明 |
| 2 | 第二篇文章 | a1 | 小明 |
post_tags
| post_id | tag |
|---|---|
| 1 | Vue |
| 1 | JS |
| 2 | JS |
3NF
第三正規化是指欄位不能依賴其他非主鍵欄位。
posts 表裡的 author_name 是由 author_id 決定的,不是由 post_id 直接決定。小明一旦改名,得更新每一筆他寫過的文章。
所以 3NF 可以再拆一張表:
posts
| post_id | title | author_id |
|---|---|---|
| 1 | 第一篇文章 | a1 |
| 2 | 第二篇文章 | a1 |
authors
| author_id | author_name |
|---|---|
| a1 | 小明 |
正規化程度決定 API 長相
正規化程度的不同,直接影響資料庫的選型與 API 的設計風格。
常見的設計大概就兩種:
- 關聯式資料庫(如 SQL):設計上鼓勵正規化,將資料拆成多張表透過 id 關聯。要拿完整資料得做 join,API 因此常回傳扁平結構,比如回傳
authorId而不是完整的author物件。 - 文件式資料庫(如 MongoDB):允許將關聯資料直接內嵌成巢狀物件存在同一個 document 裡(反正規化)。少了 join 的需求,API 自然可以一次回傳完整結構。
| SQL | MongoDB | |
|---|---|---|
| 資料結構 | 多張表,透過 id 關聯 | 單一 document,可內嵌巢狀物件 |
| 正規化 | 鼓勵正規化 | 允許反正規化 |
| API 風格 | 扁平,回傳 id | 巢狀,回傳完整物件 |
| 結構彈性 | 低,欄位需提前定義 | 高,每筆資料欄位可以不同 |
| 適合場景 | 電商訂單、會員系統 | 文章內容、使用者設定、商品規格 |
所謂結構彈性,是指每筆資料的欄位可以不一樣。以商品規格為例,衣服有尺寸、顏色,手機有容量、螢幕尺寸,食品有保存期限、成分——每個品類需要的欄位都不同。SQL 得提前定死所有欄位;MongoDB 的每個 document 可以各自長得不一樣,不需要事先知道會有哪些欄位。
補充:屬於前端的 join
有時我們會用到這種寫法,這其實就是在前端手動做一次 join:
const authorIndex = Object.fromEntries(authors.map(author => [author.id, author]))
const enrichedPosts = posts.map(post => ({
...post,
authorName: authorIndex[post.authorId]?.name
}))